
A Horse galloping through a meadow
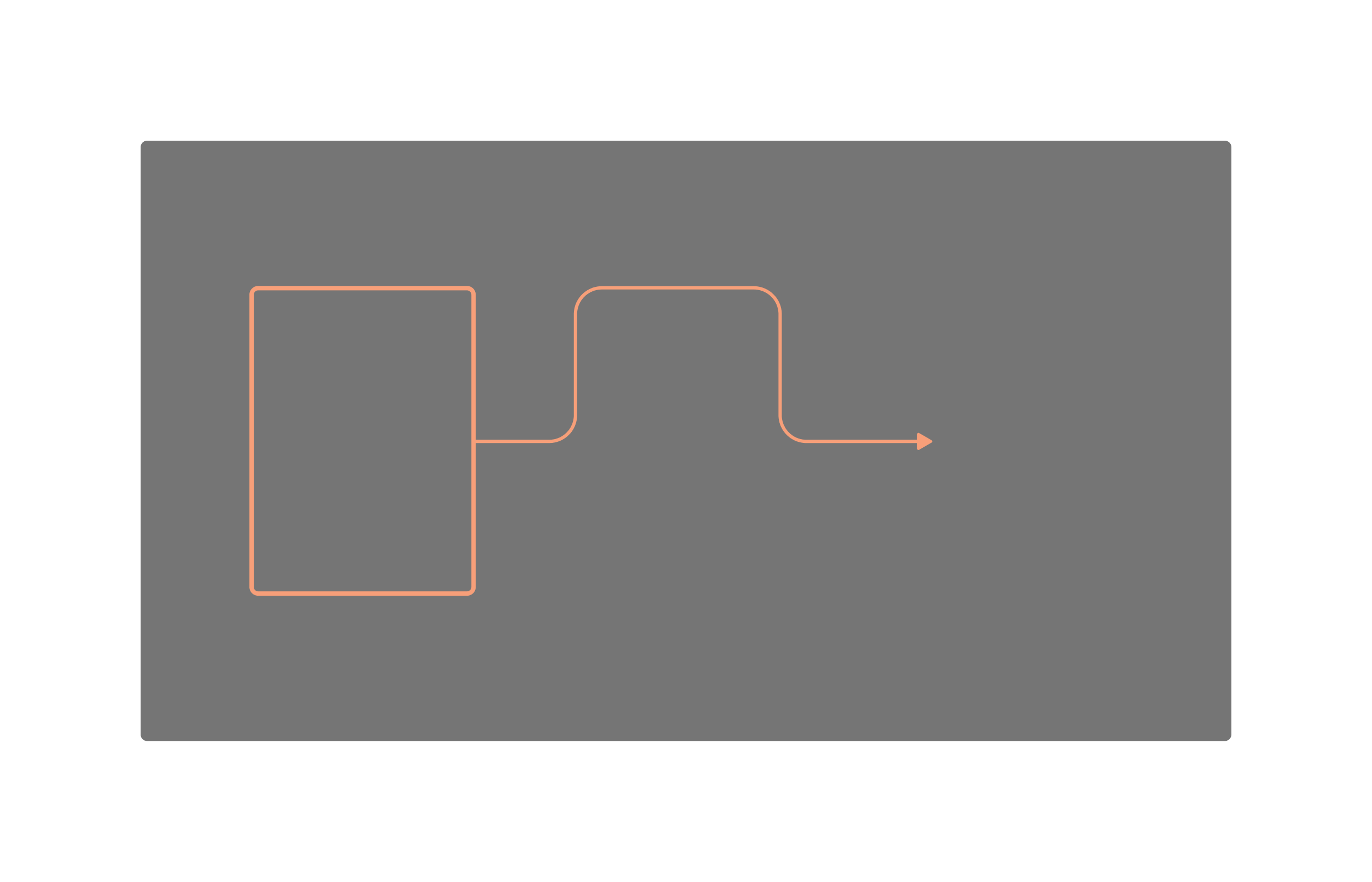



Peekaboo proposes converting attention modules of an off-the-shelf 3D UNet into masked spatio-temporal mixed attention modules. We propose to use local context for generating individual objects and hence, guide the generation process using attention masks. For each of spatial-, cross-, and temporal-attentions, we compute attention masks such that foreground pixels and background pixels attend only within their own region. We illustrate these mask computations for an input mask which changes temporally as shown on the left. Green pixels are background pixels and orange are foreground. This masking is applied for a fixed number of steps, after which free generation is allowed. Hence, foreground and background pixels are hidden from each other before being visible, akin to a game of Peekaboo.
Peekaboo allows us to control the trajectory of an object precisely.


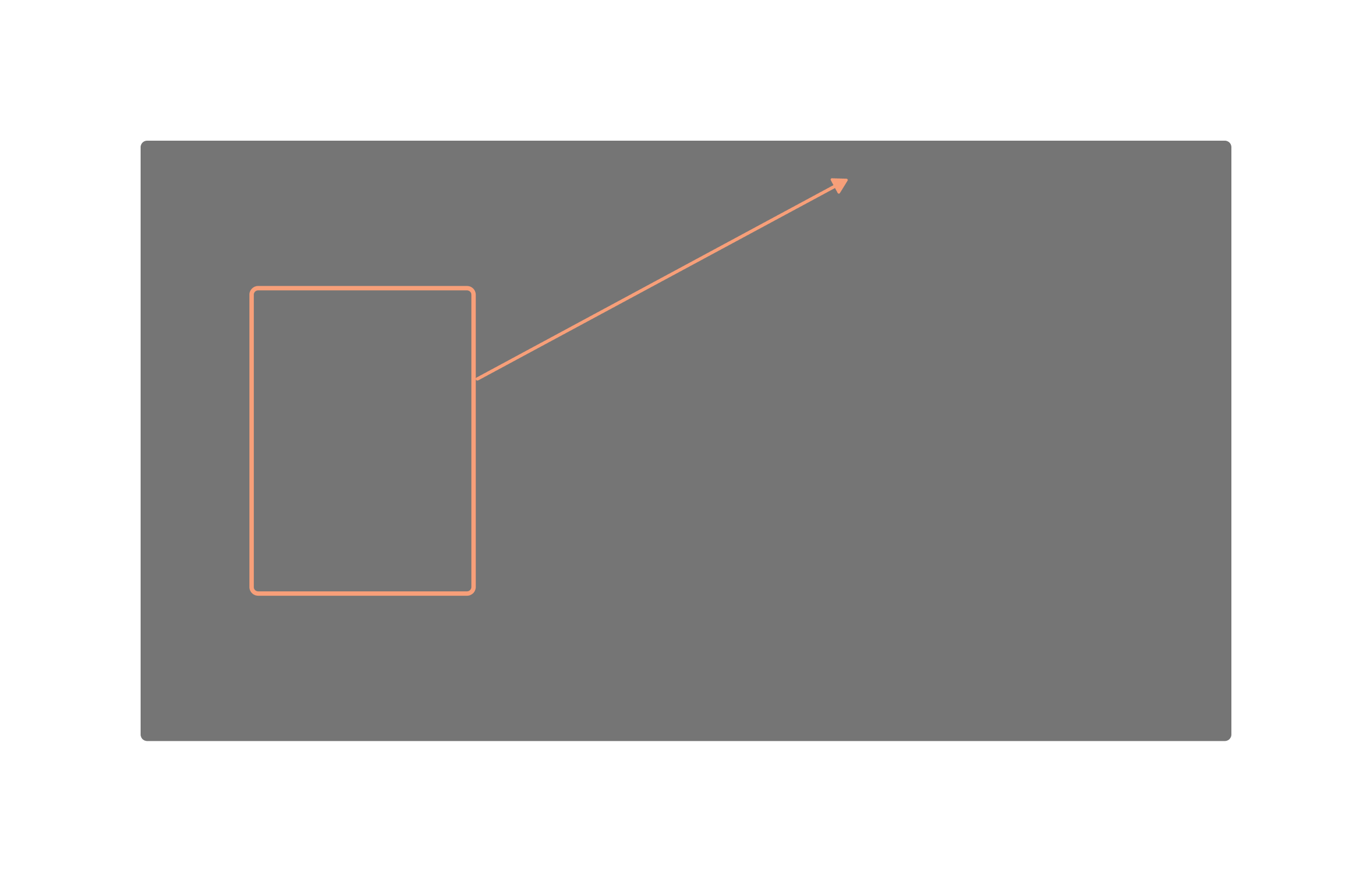

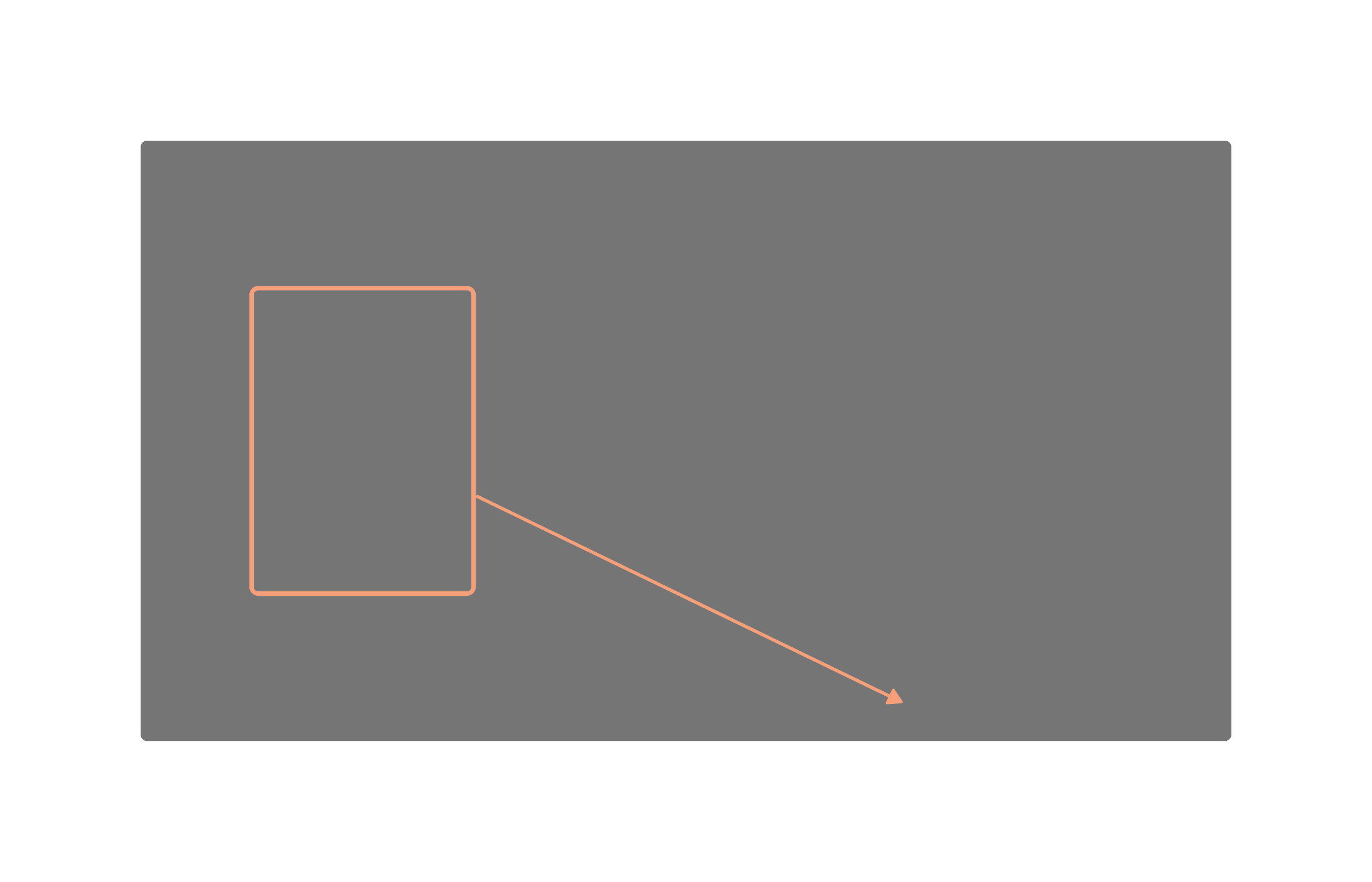

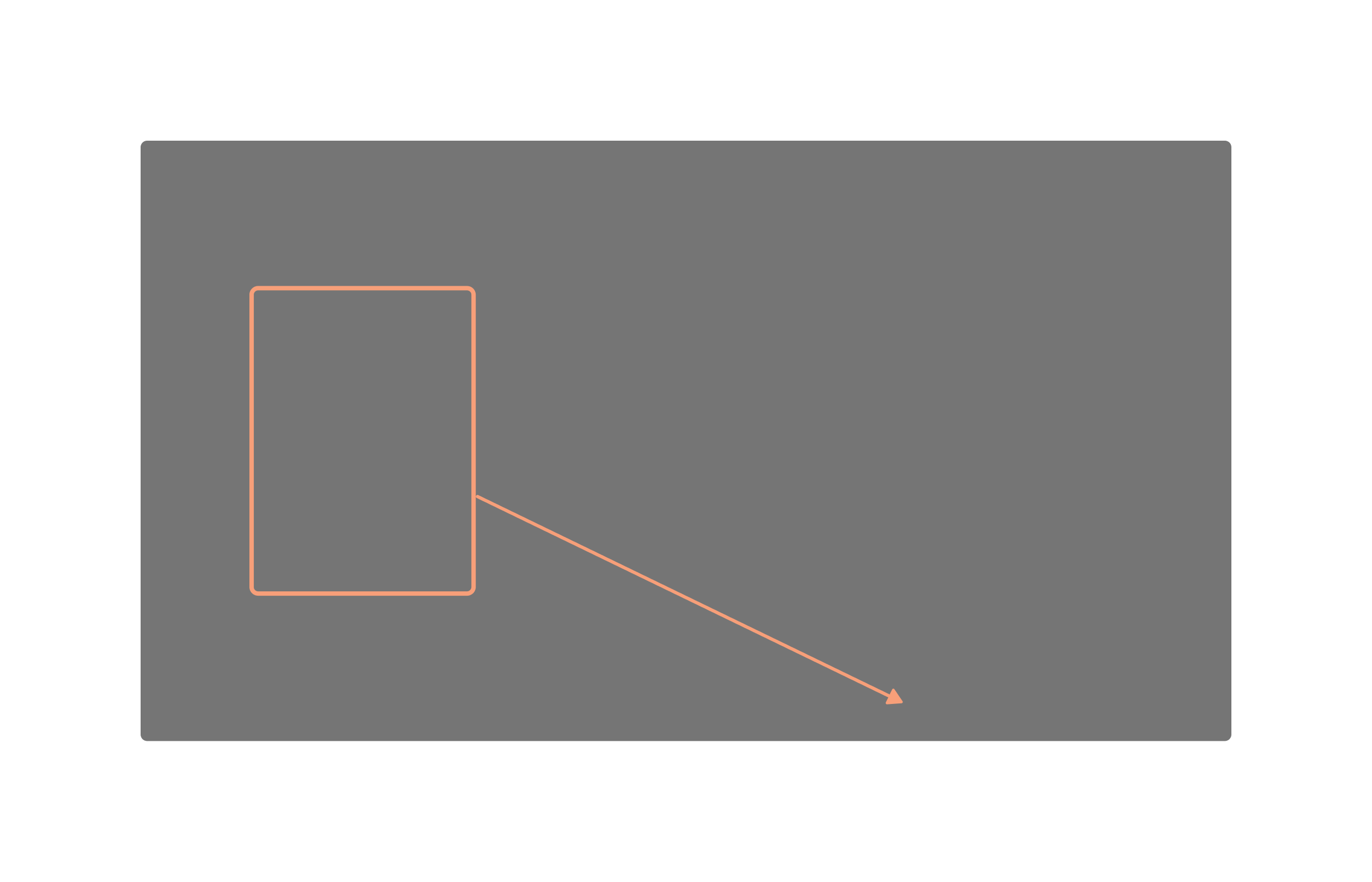

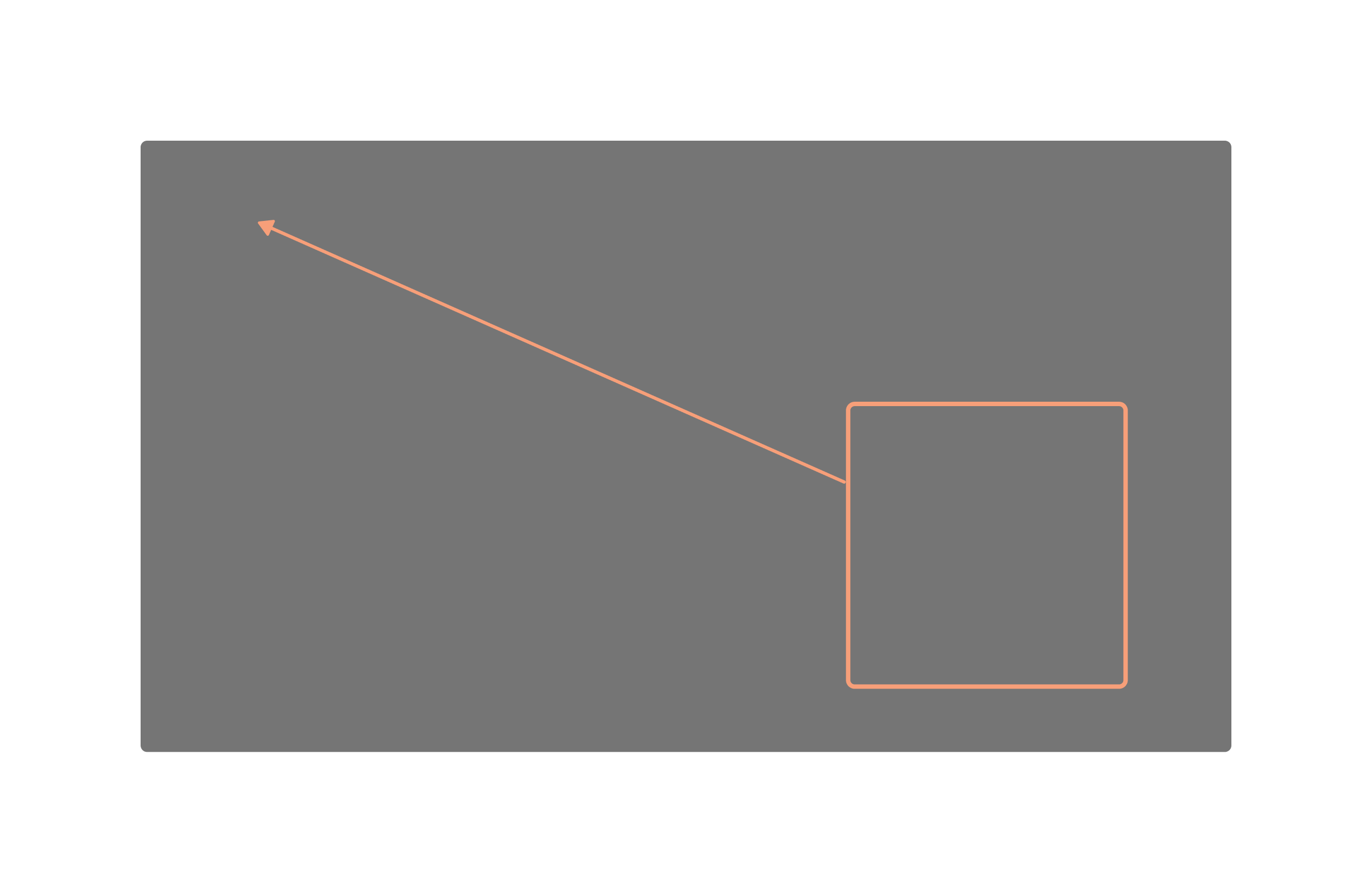





Peekaboo allows us to control the position and size of an object through bounding boxes.











We propose two new benchmark datasets for evaluating spatio-temporal control in videos.
For each prompt-bounding box input pair, we generate a video using the baseline model and our method. We then use an OwL-ViT model to label the generated video with frame-wise bounding boxes.
We propose the following metrics to measure the quality of interactive video generation models.
We present the results below.
| Method | Peekaboo | ssv2-ST | Interactive Motion Control (IMC) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| mIoU % (↑) | Coverage % (↑) | CD (↓) | AP50 % (↑) | mIoU % (↑) | Coverage % (↑) | CD (↓) | AP50 % (↑) | ||
| ZeroScope | - | 13.9 | 42.0 | 0.22 | 9.3 | 12.6 | 88 | 0.26 | 0.6 |
| ✔ | 34.7 | 56.3 | 0.17 | 39.8 | 36.3 | 96.3 | 0.12 | 33.8 | |
| ModelScope | - | 12.0 | 44.7 | 0.17 | 6.6 | 9.6 | 93.3 | 0.25 | 2.35 |
| ✔ | 33.2 | 63.7 | 0.10 | 35.8 | 36.1 | 96.6 | 0.13 | 33.3 | |
As demonstrated by mIoU and CD, the videos generated by the method endow the baselines with spatio-temporal control. The method also increases the quality of the main objects in the scene, as seen by higher coverage and AP50 scores.
Template for this webpage was taken from MotionCtrl.